Riccardo Cardin
49 min read • • Guide • Advanced

Share on:
Concurrency is a beast that every developer must face at some point in their career. It is a complex topic that requires a deep understanding of the underlying mechanisms of the programming language and the runtime environment. Java developers have dealt with concurrency for a long time, and the Java platform provides a rich set of tools to manage it. However, writing concurrent code in Java is challenging, and developers often need help writing correct and efficient concurrent programs. Fortunately, Project Loom is here to help. We already covered the introduction of virtual threads in the JVM in the article The Ultimate Guide to Java Virtual Threads. In this article, we will explore the concept of structured concurrency and how Project Loom simplifies writing concurrent code in Java.
Java 23 was released in mid-September 2024, bringing many new features and improvements to the Java platform. We’re interested in the third preview of structured concurrency, which is given a dedicated JEP: JEP 480: Structured Concurrency (Third Preview). We must enable the preview features with a directive to the compiler. We’ll use Maven as the build tool for our project. So, to allow structured concurrency in our project, we need to add the following configuration to the pom.xml file:
<build> <pluginManagement> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.10.1</version> <configuration> <release>23</release> <compilerArgs>--enable-preview</compilerArgs> </configuration> </plugin> </pluginManagement></build>We’ll use also the SLF4J logging facade with the Logback implementation for doing some logging. So, we need to add the following dependencies to the pom.xml file:
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.5.8</version></dependency>The logger we will use is the following:
private static final Logger LOGGER = LoggerFactory.getLogger("GitHubApp");Once we have set up the project, we can start writing some code to explore structured concurrency in Java. We need an example to work with in detail. This time, we’ll take the interaction with GitHub APIs (or at least a simplified version) as an example. So, without further ado, let’s start writing some code.
We’ll model the retrieval of the information needed to display the repositories of a GitHub user with some other data of the user itself. The final data structure we want to make available is the following:
record GitHubUser(User user, List<Repository> repositories) {}
record User(UserId userId, UserName name, Email email) {}
record UserId(long value) {}
record UserName(String value) {}
record Email(String value) {}
record Repository(String name, Visibility visibility, URI uri) {}
enum Visibility { PUBLIC, PRIVATE}Unfortunately, Java still lacks value classes, so we need to use regular types to model data. Once project Valhalla is completed, the UserName, and Email classes will be replaced with proper value classes.
We also define a logger that we’ll use to print some helpful information to the console. We choose to use the SLF4J logging facade with the Logback implementation. Here is the code:
private static final Logger LOGGER = LoggerFactory.getLogger("GitHubApp");How can we retrieve the needed information? The GitHub API provides a RESTful interface that we can use to retrieve it. In detail, we need to perform two requests: one to retrieve the user information and one to retrieve the user’s repositories. From the first one, we retrieve the username and email address; from the second, we retrieve the repositories.
We don’t need to implement the actual interaction with the GitHub API. So, we’ll use a simplified version of the clients. Here are the interfaces we’ll use:
interface FindUserByIdPort { User findUser(UserId userId) throws InterruptedException;}
interface FindRepositoriesByUserIdPort { List<Repository> findRepositories(UserId userId) throws InterruptedException;}The implementations of these interfaces are straightforward. They return fixed information and simulate a delay in the response. Here is the implementation of both the interfaces:
import java.net.URI;import java.time.Duration;import java.util.List;import java.util.NoSuchElementException;import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import org.slf4j.Logger;import org.slf4j.LoggerFactory;
class GitHubRepository implements FindUserByIdPort, FindRepositoriesByUserIdPort {
@Override public User findUser(UserId userId) throws InterruptedException, ExecutionException { LOGGER.info("Finding user with id '{}'", userId); delay(Duration.ofMillis(500L)); LOGGER.info("User '{}' found", userId); return new User(userId, new UserName("rcardin"), new Email("rcardin@rockthejvm.com")); }
@Override public List<Repository> findRepositories(UserId userId) throws InterruptedException, ExecutionException { LOGGER.info("Finding repositories for user with id '{}'", userId); delay(Duration.ofSeconds(1L)); LOGGER.info("Repositories found for user '{}'", userId); return List.of( new Repository( "raise4s", Visibility.PUBLIC, URI.create("https://github.com/rcardin/raise4s")), new Repository( "sus4s", Visibility.PUBLIC, URI.create("https://github.com/rcardin/sus4s"))); }}
void delay(Duration duration) throws InterruptedException { Thread.sleep(duration);}We added a convenient delay method wrapping the common Thread.sleep method.
As you might have noticed, we leave the InterruptedException unhandled, and we’ve not wrapped it into a RuntimeException. We did it on purpose. Leaving the InterruptedException in the signature signals that the execution can interrupt (or be suspended). We can call it a capability of the method. Although checked exceptions are not the best way to signal capabilities since they don’t compose well, they’re still the best approach in Java to implement an effect system in the language.
Now that we have our clients, we can start writing the code to retrieve the necessary information. We’ll start with the sequential version of the code.
interface FindGitHubUserUseCase { GitHubUser findGitHubUser(UserId userId) throws InterruptedException, ExecutionException;}
class FindGitHubUserSequentialService implements FindGitHubUserUseCase {
private final FindUserByIdPort findUserByIdPort; private final FindRepositoriesByUserIdPort findRepositoriesByUserIdPort;
public FindGitHubUserSequentialService( FindUserByIdPort findUserByIdPort, FindRepositoriesByUserIdPort findRepositoriesByUserIdPort) { this.findUserByIdPort = findUserByIdPort; this.findRepositoriesByUserIdPort = findRepositoriesByUserIdPort; }
@Override public GitHubUser findGitHubUser(UserId userId) throws InterruptedException, ExecutionException { var user = findUserByIdPort.findUser(userId); var repositories = findRepositoriesByUserIdPort.findRepositories(userId); return new GitHubUser(user, repositories); }}Despite all the ceremony Java needs, the above code is quite simple. The tasks are performed in sequence, and we expect to wait at least 1.5 seconds for the result.
Although the code could be more efficient, it has a lot of good features:
findGitHubUser method, the computation is done, and the JVM knows it can clean up all the used resources used.Let’s say the findUserByIdPort.findUser(userId) call throws an exception:
@Overridepublic User findUser(UserId userId) throws InterruptedException { LOGGER.info("Finding user with id '{}'", userId); delay(Duration.ofMillis(100L)); throw new RuntimeException("Socket timeout");}The exception is propagated to the caller, and the findRepositoriesByUserIdPort.findRepositories(userId) will never start. All resources are well-spent in this case.
We can now write the concurrent version of the code:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws InterruptedException, ExecutionException {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { var user = executor.submit(() -> findUserByIdPort.findUser(userId)); var repositories = executor.submit(() -> findRepositoriesByUserIdPort.findRepositories(userId)); return new GitHubUser(user.get(), repositories.get()); }}We’re using virtual threads in the above solution. Everybody should be familiar with them since they have been available for a while. (However, if you’re not familiar with virtual threads, please refer to our previous article The Ultimate Guide to Java Virtual Threads).
The code is quite simple. We use an ExecutorService to create a dedicated virtual thread for every submitted execution. The result is a Future<T> object that we can use to retrieve the computation result with the get method. We added the ExecutionException to our method signature because we may try to retrieve a value from a Future that completed exceptionally.
We can try to define a main method to test the code we’ve written so far:
public static void main(String[] args) throws ExecutionException, InterruptedException {
final GitHubRepository gitHubRepository = new GitHubRepository(); FindGitHubUserConcurrentService service = new FindGitHubUserConcurrentService(gitHubRepository, gitHubRepository);
final GitHubUser gitHubUser = service.findGitHubUser(new UserId(1L));
LOGGER.info("GitHub user: {}", gitHubUser);}The output of the execution of the above code is the following:
08:50:34.159 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:50:34.159 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:50:34.679 [virtual-20] INFO GitHubApp -- User 'UserId[value=1]' found08:50:35.179 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'08:50:35.183 [main] INFO GitHubApp -- GitHub user: GitHubUser[user=User[userId=UserId[value=1], name=UserName[value=rcardin], email=Email[value=rcardin@rockthejvm.com]], repositories=[Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]]The output is what we expect. Both threads start together, and their execution interleaves. After about 0.5 seconds, the user is found, and after about 1 second, the repositories are found. So far, so good.
What if the findUser method throws an exception? The network may have a glitch, or the GitHub API is down. Let’s simulate it by throwing an exception in the findUser method:
@Overridepublic User findUser(UserId userId) throws InterruptedException { LOGGER.info("Finding user with id '{}'", userId); delay(Duration.ofMillis(100L)); throw new RuntimeException("Socket timeout");}We still want to wait before throwing the exception to simulate a real-world scenario. We want to ensure the findRepositories method is not started. We can run the main method again and see what happens. The output is the following:
08:39:41.945 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:39:41.947 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:39:42.969 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.RuntimeException: Socket timeout at java.base/java.util.concurrent.FutureTask.report(FutureTask.java:122) at java.base/java.util.concurrent.FutureTask.get(FutureTask.java:191) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserConcurrentService.findGitHubUser(GitHubApp.java:115) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:125)Caused by: java.lang.RuntimeException: Socket timeout at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$GitHubRepository.findUser(GitHubApp.java:68) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserConcurrentService.lambda$findGitHubUser$0(GitHubApp.java:112)We should start to understand the problem with plain-old concurrency. The exception is thrown, but the findRepositories method is still started and executed till completion, which is a problem because we need to spend our resources wisely. We call such a situation a thread leak. However, it can be worse. Imagine, for example, that the two subtasks execute successfully but thread running the ExecutorService throws an exception after submitting them:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws InterruptedException, ExecutionException {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { var user = executor.submit(() -> findUserByIdPort.findUser(userId)); var repositories = executor.submit(() -> findRepositoriesByUserIdPort.findRepositories(userId)); throw new RuntimeException("Something went wrong"); }}If we try to run again the main method, we’ll see the following output:
08:52:18.455 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:52:18.455 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:52:18.975 [virtual-20] INFO GitHubApp -- User 'UserId[value=1]' found08:52:19.476 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'Exception in thread "main" java.lang.RuntimeException: Something went wrong at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserConcurrentService.findGitHubUser(GitHubApp.java:115) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:136)Even if the findGitHubUser went in error, both the executions of the findUser and findRepositories methods didn’t stop and complete their execution. Again, we found a thread leak. We aim that the thread executing the findGitHubUser method should be the root of the computation, the parent thread, and if it goes in error, all the computations started from it, aka its children threads, should stop. However, using plain-old concurrency, it doesn’t happen. We can’t express any association within threads.
We can implement some policy to fix the above problem. However, it takes work. We must keep track of all the threads the ExecutorService started and stop them when the parent thread goes in error. It’s a lot of work, and it’s error-prone. We can’t rely on the JVM to do it for us. We need to do it manually.
Fortunately, Project Loom provides a solution to the problem. It’s called structured concurrency.
Now that we understood the concerns with what we called plain-old concurrency let’s step back to the sequential solution for a moment:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws InterruptedException { var user = findUserByIdPort.findUser(userId); var repositories = findRepositoriesByUserIdPort.findRepositories(userId); return new GitHubUser(user, repositories);}As we said, despite being sequential and not optimized, the above computation has some excellent features.
The computation has a clear scope, and the exception handling is straightforward. We can think about the calls to the findUserByIdPort.findUser(userId) and findRepositoriesByUserIdPort.findRepositories(userId) methods as children of the findGitHubUser method. The language guarantees that when the findGitHubUser method completes, all its children’s computations are completed, too. We cannot have children tasks that outlive the parents.
We cannot have resource starvation or execution leaks, either. Again, the stack structure of modern programming languages guarantees it. Every time a function terminates its execution, the runtime can clean up all the resources used by the computation. Moreover, if the findUserByIdPort.findUser(userId) method throws an exception, the findRepositoriesByUserIdPort.findRepositories(userId) method is not started.
The code’s syntactic structure reflects the computation’s semantic structure, so it is structured.
To satisfy the above properties, we need structured concurrency. Martin Sústrik introduced the concept of structured concurrency in his blog post Structured Concurrency, and then popularized by Nathaniel J. Smith in his blog post Notes on structured concurrency, or: Go statement considered harmful.
At the core, its main objective is to provide a way to structure concurrent computation so that the syntactic structure of the code reflects the semantic structure of the concurrency, satisfying the properties we’ve seen so far for sequential code. The relationships between the parent and the children tasks form a tree.
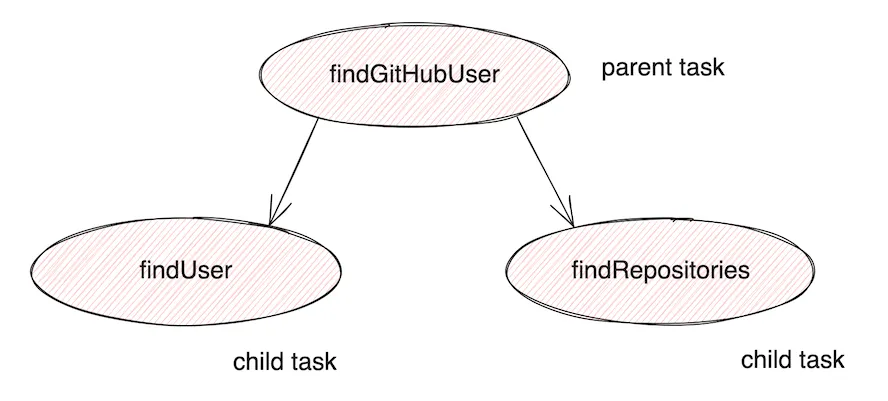
The task execution in a node is guaranteed to be completed only when all the children tasks are completed. In our example, once we set up the structured concurrency, the execution of the findGitHubUser method will be completed when the findUserByIdPort.findUser(userId) and findRepositoriesByUserIdPort.findRepositories(userId) methods are completed.
Structured concurrency has already been implemented in many programming languages. If we focused on the JVM, we could mention the Kotlin Coroutines, Scala Cats Effects Fibers, and ZIO Fibers. Now, Project Loom also introduces structured concurrency for Java.
Java implements structured concurrency through the java.util.concurrent.StructuredTaskScope type. Let’s learn how to use it directly through coding. First, we need to create the scope into which we want the properties of structured concurrency to be satisfied:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException { try (var scope = new StructuredTaskScope<>()) { // TODO return null; }}The generic T type represents the result of the computations spawned from it. Since we’ll often spawn multiple tasks with a different return type, we usually bound the type variable to Object. The type implements the AutoCloseable interface, which means we can use it inside a try-with-resources block:
public class StructuredTaskScope<T> implements AutoCloseableThe try-with-resources block delimits the scope of the structured concurrency area. We’ll see in a moment that the computation will leave the try block only when all the subtasks created inside it are completed.
Now, we need to create the subtasks. Using the structured concurrency terminology we introduced so far, the thread making the StructuredTaskScope is the parent thread, and the subtasks are the children tasks. Here is the code:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException { try (var scope = new StructuredTaskScope<>()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); // TODO return null; }}As we can see, we can spawn or fork a new child task using the fork method of the StructuredTaskScope type, which is defined as follows:
// Java SDKpublic class StructuredTaskScope<T> implements AutoCloseable { public <U extends T> Subtask<U> fork(Callable<? extends U> task)}The fork method takes a Callable<T> object as an argument and returns a Subtask<T> object. The Subtask<T> object is a pointer to the child task. The Subtask<T> is defined as an implementation of the Supplier<T> interface, which means we can retrieve the result of the computation using the get method:
// Java SDKpublic sealed interface Subtask<T> extends Supplier<T> permits SubtaskImplIf we don’t need to use any of the methods specific to the Subtask<T> type, and we only need to retrieve the result of the computation, we should use it as a Supplier<T> object. Java architects decided not to return a java.util.concurrent.Future<T> instance from the fork method to avoid confusion with the unstructured computations, and give a clear-cut with the past.
We must complete the computation before getting the result from a Subtask<T> object. Since we’re using the structured concurrency model, we want to synchronize on the executions of all the children tasks. So, we call the method join method on the scope object:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope<>()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); scope.join(); LOGGER.info("Both forked task completed"); return null; }}After joining all the forked subtasks, we can retrieve the results since all the computations are completed. Here is the last piece of our puzzle:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope<>()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); scope.join(); LOGGER.info("Both forked task completed"); return new GitHubUser(user.get(), repositories.get()); }}If we run the main method again, we’ll see the following output:
11:06:36.350 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'11:06:36.350 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'11:06:36.874 [virtual-20] INFO GitHubApp -- User 'UserId[value=1]' found11:06:37.374 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'11:06:37.377 [main] INFO GitHubApp -- Both forked task completed11:06:37.380 [main] INFO GitHubApp -- GitHub user: GitHubUser[user=User[userId=UserId[value=1], name=UserName[value=rcardin], email=Email[value=rcardin@rockthejvm.com]], repositories=[Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]]First, the two forked computations effectively interleave each other. Then, you might have noticed that the StructuredTaskScope class uses virtual threads under the hood, as seen from the thread names.
Remember, calling the join method before exiting the try block is mandatory. If we don’t do it, we’ll get a java.lang.IllegalStateException exception at runtime. For example, we can remove the call to the join method from the previous example:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope<>()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); LOGGER.info("Both forked task completed"); return new GitHubUser(user.get(), repositories.get()); }}As we said, the execution of the above code leads to the following output:
21:21:03.690 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=42]'21:21:03.690 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=42]'Exception in thread "main" java.lang.IllegalStateException: Owner did not join after forking subtasks at java.base/java.util.concurrent.StructuredTaskScope.newIllegalStateExceptionNoJoin(StructuredTaskScope.java:440) at java.base/java.util.concurrent.StructuredTaskScope.ensureJoinedIfOwner(StructuredTaskScope.java:478) at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.get(StructuredTaskScope.java:931) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.findGitHubUser(GitHubApp.java:263) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:396)It would be better to avoid such an invalid sequence of steps at compile time, but it’s a trade-off to keep the API simple.
So, we finish covering the happy path of structured concurrency and how Project Loom implements it. Now, it’s time to investigate the available policies for synchronizing forked tasks and how to handle exceptions.
Let’s say that our findUserByIdPort.findUser(userId) method will throw an exception, as we previously simulated when discussing plain-old concurrency. What happens to our structured concurrency computation? Let’s see it in action and execute it:
11:07:17.590 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'11:07:17.590 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'11:07:18.616 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'11:07:18.632 [main] INFO GitHubApp -- Both forked task completedException in thread "main" java.lang.IllegalStateException: Result is unavailable or subtask did not complete successfully at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.get(StructuredTaskScope.java:940) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.findGitHubUser(GitHubApp.java:156) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:166)The above log is exciting. First, the parent thread waits for the end of both tasks before continuing. So, the tree structure of the computation is respected. The computation went in error when we tried to get the result from the failed computation. Moreover, the second task was not canceled once the first went into error.
The issue is the type of scope we chose to use. The StructuredTaskScope<T> doesn’t implement any advanced policy for error handling. It’s a simple blueprint to build advanced policies. At the moment of writing, project Loom comes with two implementations of the StructuredTaskScope<T> type: java.util.concurrent.StructuredTaskScope.ShutdownOnFailure and java.util.concurrent.StructuredTaskScope.ShutdownOnSuccess
Let’s start with analyzing the first one. We’ll use it directly in our example (the one that doesn’t throw any exception) and see what happens. Here is the code:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); scope.join(); LOGGER.info("Both forked task completed"); return new GitHubUser(user.get(), repositories.get()); }}First, we execute the case in which no exception is thrown. The output is the following:
08:21:05.040 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:21:05.041 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:21:05.583 [virtual-20] INFO GitHubApp -- User 'UserId[value=1]' found08:21:06.087 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'08:21:06.108 [main] INFO GitHubApp -- Both forked task completed08:21:06.111 [main] INFO GitHubApp -- GitHub user: GitHubUser[user=User[userId=UserId[value=1], name=UserName[value=rcardin], email=Email[value=rcardin@rockthejvm.com]], repositories=[Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]]The behavior is the same as the execution with the StructuredTaskScope type as expected. Now, let’s see what happens when the findUserByIdPort.findUser(userId) method throws an exception:
08:22:42.466 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:22:42.466 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:22:42.590 [main] INFO GitHubApp -- Both forked task completedException in thread "main" java.lang.IllegalStateException: Result is unavailable or subtask did not complete successfully at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.get(StructuredTaskScope.java:940) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.findGitHubUser(GitHubApp.java:157) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:167)Well, the output looks very promising. When the first task failed, the second task was stopped (canceled). The parent task was not stopped, and a java.lang.IllegalStateException exception was thrown when we tried to get the result from the failed computation. So, we solved one of the problems of unstructured concurrency, thread leaks, and resource starvation. It’s a good step forward.
However, the thrown exception was not the original one the child computation threw. We completely lost the original cause of the error. However, we can do better. The StructuredTaskScope.ShutdownOnFailure scope adds a method to the available ones, throwIfFailed. As the documentation said, the method throws if any subtasks fail. The method throws a java.util.concurrent.ExecutionException exception set with the original exception as its cause. If no subtask fails, the process usually returns.
We first change our code to see the new behavior in action:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); LOGGER.info("Both forked task completed");
scope.join().throwIfFailed();
return new GitHubUser(user.get(), repositories.get()); }}If we run the code, we’ll notice that the behavior is expected. The output is the following:
08:34:53.701 [main] INFO GitHubApp -- Both forked task completed08:34:53.701 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:34:53.700 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.RuntimeException: Socket timeout at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnFailure.throwIfFailed(StructuredTaskScope.java:1324) at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnFailure.throwIfFailed(StructuredTaskScope.java:1301) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.findGitHubUser(GitHubApp.java:156) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:168)Caused by: java.lang.RuntimeException: Socket timeout at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$GitHubRepository.findUser(GitHubApp.java:68) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.lambda$findGitHubUser$0(GitHubApp.java:151) at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:893) at java.base/java.lang.VirtualThread.run(VirtualThread.java:329)If we want to change the type of the exception thrown by the throwIfFailed, the method comes with an override that takes a function as input to map the exception:
// Java SDKpublic <X extends Throwable> void throwIfFailed(Function<Throwable, ? extends X> esf) throws XLet’s say we re-throw exactly the original exception. We can do it using the identity function:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws Throwable { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var user = scope.fork(() -> findUserByIdPort.findUser(userId)); var repositories = scope.fork(() -> findRepositoriesByUserIdPort.findRepositories(userId)); LOGGER.info("Both forked task completed");
scope.join().throwIfFailed(Function.identity());
return new GitHubUser(user.get(), repositories.get()); }}If we run the code, we’ll see the following output:
08:46:38.451 [main] INFO GitHubApp -- Both forked task completed08:46:38.450 [virtual-20] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:46:38.451 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'Exception in thread "main" java.lang.RuntimeException: Socket timeout at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$GitHubRepository.findUser(GitHubApp.java:70) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.lambda$findGitHubUser$0(GitHubApp.java:153) at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:893) at java.base/java.lang.VirtualThread.run(VirtualThread.java:329)The logs say that we successfully re-threw the original exception. However, there is an issue we should be aware of. The throwIfFailed method takes a function with a Throwable instance as input to Throwable, which means that the function will also be called for terminal errors, such as OutOfMemoryError or StackOverflowError. As a rule, we should avoid catching such errors and let the JVM handle them. So, if we need to process the error with the throwIfFailed method, remember to check if the input is an instance of Exception or Error and act accordingly:
scope.join().throwIfFailed(throwable -> { if (throwable instanceof Exception) { // Handle the exception } else throw (Error) throwable;});It’s easy to use the StructuredTaskScope.ShutdownOnFailure policy to implement a structured concurrency primitive available in all the libraries implementing some form of concurrency: We’re talking about the par function. The par function takes two tasks and returns the result of both, or it stops if any of the two computations fail. For those who are familiar with Scala Cats Effects or ZIO libraries, the par function is a typical primitive. Here is the code:
record Pair<T1, T2>(T1 first, T2 second) {}
static <T1, T2> Pair<T1, T2> par(Callable<T1> first, Callable<T2> second) throws InterruptedException, ExecutionException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var firstTask = scope.fork(first); var secondTask = scope.fork(second); scope.join().throwIfFailed(); return new Pair<>(firstTask.get(), secondTask.get()); }}If you have noticed, the above code is what we did in the findGitHubUser method. We can now refactor the method to use the par function:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { var result = par( () -> findUserByIdPort.findUser(userId), () -> findRepositoriesByUserIdPort.findRepositories(userId) ); return new GitHubUser(result.first(), result.second());}The StructuredTaskScope.ShutdownOnFailure is not the only policy available. The JDK has another built-in policy, the StructuredTaskScope.ShutdownOnSuccess. The policy is similar to the ShutdownOnFailure one but stops the computation at the first subtask that completes successfully. Let’s build an example to analyze the function in detail.
Imagine that we noticed that retrieving all the user’s repositories is a costly operation—moreover, the repositories of a user change very rarely. So, we decide to build a cached version of the findRepositories method. First, we need to define an implementation of the port that uses a cache to store the result of the computation. Here is the code:
class FindRepositoriesByUserIdCache implements FindRepositoriesByUserIdPort {
private final Map<UserId, List<Repository>> cache = new HashMap<>();
public FindRepositoriesByUserIdCache() { cache.put( new UserId(42L), List.of( new Repository( "rockthejvm.github.io", Visibility.PUBLIC, URI.create("https://github.com/rockthejvm/rockthejvm.github.io")))); }
@Override public List<Repository> findRepositories(UserId userId) throws InterruptedException { // Simulates access to a distributed cache (Redis?) delay(Duration.ofMillis(100L)); final List<Repository> repositories = cache.get(userId); if (repositories == null) { LOGGER.info("No cached repositories found for user with id '{}'", userId); throw new NoSuchElementException( "No cached repositories found for user with id '%s'".formatted(userId)); } return repositories; }
public void addToCache(UserId userId, List<Repository> repositories) throws InterruptedException { // Simulates access to a distributed cache (Redis?) delay(Duration.ofMillis(100L)); cache.put(userId, repositories); }}As you can see, we’re simulating a distributed cache like Redis with an in-memory map and a delay to simulate the network latency. We’re not paying attention to concurrent access to the map since the article’s main topic is not the simultaneous access of data structures. Please don’t use the above code in production. Moreover, the behavior in case the repositories are not found in the cache is rude. The method throws a NoSuchElementException exception. However, it’ll be clear in a moment why we did it.
At startup time, the only cached repositories are those of the user with UserId(42L).
Now, we can implement a pimped version of our original findRepositories method. It’ll spawn two tasks: one to retrieve the repositories from the cache and one to retrieve the repositories from the GitHub API. The first task that is completed successfully will stop the computation:
static class GitHubCachedRepository implements FindRepositoriesByUserIdPort {
private final FindRepositoriesByUserIdPort repository; private final FindRepositoriesByUserIdCache cache;
GitHubCachedRepository( FindRepositoriesByUserIdPort repository, FindRepositoriesByUserIdCache cache) { this.repository = repository; this.cache = cache; }
@Override public List<Repository> findRepositories(UserId userId) throws InterruptedException, ExecutionException { try (var scope = new StructuredTaskScope.ShutdownOnSuccess<List<Repository>>()) { scope.fork(() -> cache.findRepositories(userId)); scope.fork( () -> { final List<Repository> repositories = repository.findRepositories(userId); cache.addToCache(userId, repositories); return repositories; }); return scope.join().result(); } }}We used the StructuredTaskScope.ShutdownOnSuccess policy to implement our new use case. Let’s spot the differences with the previous policy. First, the type of the scope is StructuredTaskScope.ShutdownOnSuccess<List<Repository>>. The type parameter is the type of computation result. Then, we didn’t give much attention to the Subtask objects returned by the fork method. As we can see, we call the result method on the scope object to retrieve the result of the computation. We need to determine which of the two tasks was completed successfully. The result method returns the result of the first task completed successfully.
Let’s test the new implementation. We can use the main method to do it:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository(); final FindRepositoriesByUserIdCache cache = new FindRepositoriesByUserIdCache(); final FindRepositoriesByUserIdPort gitHubCachedRepository = new GitHubCachedRepository(gitHubRepository, cache);
final List<Repository> repositories = gitHubCachedRepository.findRepositories(new UserId(1L));
LOGGER.info("GitHub user's repositories: {}", repositories);}We expect the cache to throw an exception since the repositories of the user with UserId(1L) are not cached and the repository to complete the execution successfully. As we said, the StructuredTaskScope.ShutdownOnSuccess scope waits for the first successful task. The output of the execution is, in fact, the following:
09:43:21.679 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'09:43:21.779 [virtual-20] INFO GitHubApp -- No cached repositories found for user with id 'UserId[value=1]'09:43:22.702 [virtual-22] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'09:43:22.812 [main] INFO GitHubApp -- GitHub user's repositories: [Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]As we can see, the cache task throws an exception, and the repository task completes successfully. The computation stops, and the result is the one we expect.
Now, we can simulate that the cache completes successfully, finding the user’s repositories in memory. As you might remember, the user’s repositories with UserId(42L) are in the cache. Let’s change our main method to test the new scenario:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository(); final FindRepositoriesByUserIdCache cache = new FindRepositoriesByUserIdCache(); final FindRepositoriesByUserIdPort gitHubCachedRepository = new GitHubCachedRepository(gitHubRepository, cache);
final List<Repository> repositories = gitHubCachedRepository.findRepositories(new UserId(42L));
LOGGER.info("GitHub user's repositories: {}", repositories);}The output of the execution is the following:
21:36:32.901 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=42]'21:36:33.014 [main] INFO GitHubApp -- GitHub user's repositories: [Repository[name=rockthejvm.github.io, visibility=PUBLIC, uri=https://github.com/rockthejvm/rockthejvm.github.io]]The task that retrieve the repositories directly from GitHub started. However, since the cache task was completed successfully, it was canceled to avoid wasting resources. We’ve achieved our goal.
What if both tasks throw an exception? We can see it in action by changing the findRepositories of the GitHubRepository class to throw an exception. Here is the code:
@Override@Overridepublic List<Repository> findRepositories(UserId userId) throws InterruptedException { LOGGER.info("Finding repositories for user with id '{}'", userId); delay(Duration.ofSeconds(1L)); throw new RuntimeException("Socket timeout");}We must change the user used during the search to let the cache crash again.
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository(); final FindRepositoriesByUserIdCache cache = new FindRepositoriesByUserIdCache(); final FindRepositoriesByUserIdPort gitHubCachedRepository = new GitHubCachedRepository(gitHubRepository, cache); final List<Repository> repositories = gitHubCachedRepository.findRepositories(new UserId(1L)); LOGGER.info("GitHub user's repositories: {}", repositories);}There we go! Let’s execute the code:
16:18:21.615 [virtual-22] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'16:18:21.714 [virtual-20] INFO GitHubApp -- No cached repositories found for user with id 'UserId[value=1]'Exception in thread "main" java.util.concurrent.ExecutionException: java.util.NoSuchElementException: No cached repositories found for user with id 'UserId[value=1]' at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnSuccess.result(StructuredTaskScope.java:1152) at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnSuccess.result(StructuredTaskScope.java:1116) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$GitHubCachedRepository.findRepositories(GitHubApp.java:104) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:257)As we can see, the log reports the first exception thrown by the cache task. The second exception, the RuntimeException("Socket timeout"), was caught by the scope but it was suppressed. The StructuredTaskScope.ShutdownOnSuccess re-throws the first exception if all the tasks throw an exception.
We can remap the exception thrown by the result method as we did for the throwIfFailed method. The result method has an override that takes a function as input to map the exception:
// Java SDKpublic <X extends Throwable> T result(Function<Throwable, ? extends X> esf) throws XIt’s a bit weird, but the function passed to the result method still maps the exception thrown by the result method. So, we can use the identity function to re-throw the original exception:
scope.join().result(Function.identity());The same warnings about exceptions’ remapping we gave for the throwIfFailed method hold for the result method.
We can use the StructuredTaskScope.ShutdownOnSuccess to implement another concurrency primitive present in other well-known libraries, such as ZIO and Softwaremill Ox: The raceAll function. The raceAll function takes a list of tasks and returns the result of the first successfully completed task. If all the tasks throw an exception, the first exception thrown is re-thrown. For the sake of simplicity, we’ll implement a simplified version that takes only two subtasks.
Here is how we can implement it in Java using the StructuredTaskScope.ShutdownOnSuccess policy:
static <T> T raceAll(Callable<T> first, Callable<T> second) throws InterruptedException, ExecutionException { try (var scope = new StructuredTaskScope.ShutdownOnSuccess<T>()) { scope.fork(first); scope.fork(second); return scope.join().result(); }}Let’s rewrite the GitHubCachedRepository.findRepositories method using the raceAll function we just implemented:
@Overridepublic List<Repository> findRepositories(UserId userId) throws InterruptedException, ExecutionException { return raceAll( () -> cache.findRepositories(userId), () -> { final List<Repository> repositories = repository.findRepositories(userId); cache.addToCache(userId, repositories); return repositories; });}If you’re familiar with concurrency primitives, you might be asking how we can implement the race primitive. The race function should execute two tasks concurrently and return the result of the completed task, whether successful or not. ZIO and Cats Effects libraries use it to implement the timeout function for example. The available subclasses of the StructuredTaskScope don’t offer a way to implement the race function directly. We need to create our policy to implement it.
Let’s do it and deepen our knowledge of structured concurrency internal mechanisms.
As we said, we want to implement a structured concurrency policy that mimics the behavior of the race function. The race function should execute two tasks concurrently and return the result of the first task that is completed, whether successful or not. Let’s do it one step at a time.
Implementing a custom policy always starts extending the StructuredTaskScope type. The base class implements all the mechanisms to synchronize the forked tasks:
class ShutdownOnResult<T> extends StructuredTaskScope<T> { // TODO}We want our policy to return a result of type T, similar to what is done by the ShutdownOnSuccess<T> type. Then, we made the new policy generic on T. The StructuredTaskScope is a concrete class with no abstract method to implement. The documentation tells us that we need to override the handleComplete method:
static class ShutdownOnResult<T> extends StructuredTaskScope<T> {
@Override protected void handleComplete(Subtask<? extends T> subtask) { // TODO }}The method takes a Subtask<T> in input. The scope calls the handleComplete every time a subtask forked by the scope completes. The input subtask is the one that completes.
Now, we can extract the result of the computation from the subtask. The Subtask type exposes two methods. The first is the T get() method we used so far that returns the computed value in case of success. If you remember, the get method comes from the Supplier<T> interface that the Subtask<T> implements. The second method is the Throwable exception(), which returns the exception thrown by the computation in case of failure.
However, as we already saw in the previous examples, we can’t call get if the computation fails; otherwise, the method will throw an IllegalStateException. On the other hand, if the computation succeeds, we can’t call the exception method, which will have the same behavior.
We need to know if the computation was completed successfully. The Subtask type comes with the property State state(), which returns the computation’s state as an enum. The enum has three values: UNAVAILABLE, SUCCESS, and FAILED.
After completing it successfully, A subtask will be in the SUCCESS state. The get method will return the result of the computation. If it completes with an exception, a subtask will be in the FAILED state. The exception method will return the exception thrown. A subtask will be in the UNAVAILABLE state if the computation is not completed yet, for example, if we call the get method before having join the scope or if the subtask was canceled (we’ll see in the following sections what does it mean).
We need to use some state that can store the result of the first successful result or the exception thrown by the first task that failed:
static class ShutdownOnResult<T> extends StructuredTaskScope<T> { private T firstResult; private Throwable firstException;
@Override protected void handleComplete(Subtask<? extends T> subtask) { // TODO }}We need to synchronize the access to the state since the handleComplete method is called concurrently by the forked tasks. There are a million ways to do it. The only one we don’t want to use is calling a synchronized block. As you might remember, virtual threads don’t work well with synchronized blocks since the carrier thread is pinned to the virtual thread, and so it blocks waiting for the lock to be released.
We can use a ReentrantLock to synchronize the access to the state instead, which doesn’t suffer the above problem:
static class ShutdownOnResult<T> extends StructuredTaskScope<T> { private final Lock lock = new ReentrantLock(); private T firstResult; private Throwable firstException;
@Override protected void handleComplete(Subtask<? extends T> subtask) { // TODO }We want to synchronize access to the state in both reading and writing. We can optimize access to the mutable state further, but the article aims to show how to implement a custom policy for structured concurrency. So, we’ll keep the code simple:
@Overrideprotected void handleComplete(Subtask<? extends T> subtask) { switch (subtask.state()) { case FAILED -> { lock.lock(); try { if (firstException == null) { firstException = subtask.exception(); shutdown(); } } finally { lock.unlock(); } } case SUCCESS -> { lock.lock(); try { if (firstResult == null) { firstResult = subtask.get(); shutdown(); } } finally { lock.unlock(); } } case UNAVAILABLE -> super.handleComplete(subtask); }}As we can see, the handleComplete method checks the state of the given subtask and sets the proper variable representing our state accordingly. After that, the method invokes the shutdown method. The shutdown method comes from the StructuredTaskScope, and it stops all the pending subtasks forked by the scope. We will see how it works in detail in the following sections.
Now that we have the first result or exception thrown by the forked tasks, we need a way to retrieve it. We can add a method to the ShutdownOnResult type that returns the result of the computation or throws the first exception thrown. The method looks like a mix between the ShutdownOnFailure.throwIfFailed and the ShutdownOnSuccess.result methods, and we called it resultOrThrow:
public T resultOrThrow() throws ExecutionException { ensureOwnerAndJoined(); if (firstException != null) { throw new ExecutionException(firstException); } return firstResult;}As you might notice, the first thing we do in the resultOrThrow method is the ensureOwnerAndJoined function. The method is protected and defined in the StructuredTaskScope class. It’s a utility method that checks if the current thread is the owner of the scope and if the scope is joined. Checking if the thread calling the function is the owner of the scope is crucial since we want the scope to stay within the structured concurrency context. As we’ll see in the next section, all the properties of structured concurrency hold if the structure of the code respects the structure of the concurrency, which means that the parent-children relationship should be respected. So, if the scope escapes the structured concurrency context, calling the method ensureOwnerAndJoined will throw a java.lang.WrongThreadException exception.
Finally, the complete code of the ShutdownOnResult policy is the following:
static class ShutdownOnResult<T> extends StructuredTaskScope<T> { private final Lock lock = new ReentrantLock(); private T firstResult; private Throwable firstException;
@Override protected void handleComplete(Subtask<? extends T> subtask) { switch (subtask.state()) { case FAILED -> { lock.lock(); try { if (firstException == null) { firstException = subtask.exception(); shutdown(); } } finally { lock.unlock(); } } case SUCCESS -> { lock.lock(); try { if (firstResult == null) { firstResult = subtask.get(); shutdown(); } } finally { lock.unlock(); } } case UNAVAILABLE -> super.handleComplete(subtask); } }
@Override public ShutdownOnResult<T> join() throws InterruptedException { super.join(); return this; }
public T resultOrThrow() throws ExecutionException { ensureOwnerAndJoined(); if (firstException != null) { throw new ExecutionException(firstException); } return firstResult; }}Let’s try our new policy in action. For example, say that we want to retrieve a user’s repositories within a given interval or give up otherwise. We want the computation to be shut down correctly in both cases, as we did in all the previous examples. We can use the new and shiny ShutdownOnResult policy to implement the use case:
static class FindRepositoriesByUserIdWithTimeout { final FindRepositoriesByUserIdPort delegate; FindRepositoriesByUserIdWithTimeout(FindRepositoriesByUserIdPort delegate) { this.delegate = delegate; } List<Repository> findRepositories(UserId userId, Duration timeout) throws InterruptedException, ExecutionException { try (var scope = new ShutdownOnResult<List<Repository>>()) { scope.fork(() -> delegate.findRepositories(userId)); scope.fork( () -> { delay(timeout); throw new TimeoutException("Timeout of %s reached".formatted(timeout)); }); return scope.join().resultOrThrow(); } }}We can now see the effect of the timeout trying to get the repositories of a user within 500 milliseconds:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository(); final FindRepositoriesByUserIdWithTimeout findRepositoriesWithTimeout = new FindRepositoriesByUserIdWithTimeout(gitHubRepository);
final List<Repository> repositories = findRepositoriesWithTimeout.findRepositories(new UserId(1L), Duration.ofMillis(500L));
LOGGER.info("GitHub user's repositories: {}", repositories);}As expected, the execution output is the following:
09:13:08.611 [virtual-20] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'Exception in thread "main" java.util.concurrent.ExecutionException: java.util.concurrent.TimeoutException: Timeout of PT0.5S reached at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$ShutdownOnResult.resultOrThrow(GitHubApp.java:334) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindRepositoriesByUserIdWithTimeout.findRepositories(GitHubApp.java:64) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:365)Caused by: java.util.concurrent.TimeoutException: Timeout of PT0.5S reached at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindRepositoriesByUserIdWithTimeout.lambda$findRepositories$1(GitHubApp.java:62) at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:893) at java.base/java.lang.VirtualThread.run(VirtualThread.java:329)The computation retrieving the repositories started but couldn’t complete within the given interval, so it was canceled. Whereas, if we increase the timeout to 1.5 seconds, the computation retrieves the repositories successfully:
09:15:42.083 [virtual-20] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'09:15:43.100 [virtual-20] INFO GitHubApp -- Repositories found for user 'UserId[value=1]'09:15:43.122 [main] INFO GitHubApp -- GitHub user's repositories: [Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]We have all the building blocks to develop our race function, which returns the result of the first completed task, both successful and not. Here is the code:
static <T> T race(Callable<T> first, Callable<T> second) throws InterruptedException, ExecutionException { try (var scope = new ShutdownOnResult<T>()) { scope.fork(first); scope.fork(second); return scope.join().resultOrThrow(); }}We can implement the timeout function once we have the race function. The timeout function takes a task and a duration as input. The function returns the task result if the task is completed within the given duration. If the task isn’t completed within the given duration, the function throws a TimeoutException exception. Here is the code:
static <T> T timeout(Duration timeout, Callable<T> task) throws InterruptedException, ExecutionException { return race( task, () -> { delay(timeout); throw new TimeoutException("Timeout of %s reached".formatted(timeout)); });}We can rewrite the above example using the timeout function, thus avoiding the definition of the FindRepositoriesByUserIdWithTimeout class at all:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository(); final List<Repository> repositories = timeout(Duration.ofMillis(500L), () -> gitHubRepository.findRepositories(new UserId(1L)));
LOGGER.info("GitHub user's repositories: {}", repositories);}Building up a function that implements a timeout on concurrent computation was fun, and we learned a lot during the process. However, the StructuredTaskScope type already implements it. There is an override of the join function that takes an Instant as input:
public StructuredTaskScope<T> joinUntil(Instant deadline)The function waits for the scope to complete for the given duration. If the scope isn’t complete within the given duration, the function throws a TimeoutException exception. Then, we can rewrite the timeout function just using the ShutdownOnFailure policy and the joinUntil method:
static <T> T timeout2(Duration timeout, Callable<T> task) throws InterruptedException, TimeoutException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var result = scope.fork(task); scope.joinUntil(Instant.now().plus(timeout)); return result.get(); }}By the way, we implemented the race function through the ShutdownOnResult policy, so it was not a waste of time.
In the previous section, we saw that the StructuredTaskScope type comes with a shutdown method. We called the method in the handleComplete method of the ShutdownOnResult policy to stop the computation as soon as the first task was completed successfully or failed. The shutdown method stops all the pending subtasks forked by the scope.
All the available policies of the StructuredTaskScope call the shutdown method in case of error or success. The ShudownOnFailure policy, as the name suggests, calls the shutdown method in case of an error in one of the forked computations:
// Java SDK@Overrideprotected void handleComplete(Subtask<?> subtask) { if (subtask.state() == Subtask.State.FAILED && firstException == null && FIRST_EXCEPTION.compareAndSet(this, null, subtask.exception())) { super.shutdown(); }}As we did for our ShutdownOnResult implementation, the shutdown method is called in the handleComplete method, which means when a forked task completes. In the above case, the shutdown policy tests if the computation threw an exception, and in case it was the first exception thrown, it is called the shutdown method.
The ShutdownOnSuccess policy works similarly. It calls the shutdown method when it gets the first successful result from one of the forked tasks:
// Java SDK@Overrideprotected void handleComplete(Subtask<? extends T> subtask) { if (firstResult != null) { // already captured a result return; } if (subtask.state() == Subtask.State.SUCCESS) { // task succeeded T result = subtask.get(); Object r = (result != null) ? result : RESULT_NULL; if (FIRST_RESULT.compareAndSet(this, null, r)) { super.shutdown(); } } else if (firstException == null) { // capture the exception thrown by the first subtask that failed FIRST_EXCEPTION.compareAndSet(this, null, subtask.exception()); }}As you should remember, failures accumulate and don’t force the scope to shut down.
Last but not least, if the policy hasn’t called the shutdown before the scope’s execution completion, the shutdown method is called by the close method:
// Java SDK@Overridepublic void close() { ensureOwner(); int s = state; if (s == CLOSED) return; try { if (s < SHUTDOWN) implShutdown(); flock.close(); } finally { state = CLOSED; } // throw ISE if the owner didn't attempt to join after forking if (forkRound > lastJoinAttempted) { lastJoinCompleted = forkRound; throw newIllegalStateExceptionNoJoin(); }}Despite many implementation details, the above code says that the shutdown method is called if the scope is still open when the close method is called. As you can see, the scope has an internal status, and the possible statuses are:
// Java SDK// states: OPEN -> SHUTDOWN -> CLOSEDprivate static final int OPEN = 0; // initial stateprivate static final int SHUTDOWN = 1;private static final int CLOSED = 2;
private volatile int state;A scope starts in the OPEN state at creation time since the variable that stores the state is an int, and its initial value is always set to zero by the JVM. Then, if the shutdown method is called, the scope moves to the SHUTDOWN state:
// Java SDKpublic void shutdown() { ensureOwnerOrContainsThread(); int s = ensureOpen(); // throws ISE if closed if (s < SHUTDOWN && implShutdown()) flock.wakeup();}
private boolean implShutdown() { shutdownLock.lock(); try { if (state < SHUTDOWN) { // prevent new threads from starting flock.shutdown(); // set status before interrupting tasks state = SHUTDOWN; // interrupt all unfinished threads interruptAll(); return true; } else { // already shutdown return false; } } finally { shutdownLock.unlock(); }}Finally, the close() method moves the state of the scope to CLOSE, as we saw. The curious reader should have noticed that the scope uses jdk.internal.misc.ThreadFlock to manage threads forked by a scope. ThreadFlock is a low-level mechanism to manage correlated threads in the JDK. It’s so low-level that it is even hard to find documentation associated with it.
By the way, we said that calling the shutdown method stops all the pending subtasks forked by the scope. The above implementation shows how the method stops the task, calling the interruptAll private method. Here is its implementation of the core of the method:
// Java SDKprivate void implInterruptAll() { flock.threads() .filter(t -> t != Thread.currentThread()) .forEach(t -> { try { t.interrupt(); } catch (Throwable ignore) { } });}As we can see, there is no magic under the stop of uncompleted computation. The (virtual) threads owning the tasks are interrupted by the scope. As you might remember, interruption (or canceling) is a cooperative mechanism in Java. A thread is eligible for interruption if it calls a method that throws an InterruptedException exception or if it checks the interruption status of the thread. Luckily, almost any blocking operation in the JDK can be interrupted, so the interruption mechanism works well. However, creating a computation that can’t be interrupted when dealing with CPU-intensive tasks is easy.
Let’s make an example. Imagine we want to mine bitcoins while waiting for a user’s repositories. We can implement the mineBitcoins method as follows:
record Bitcoin(String hash) {}
static Bitcoin mineBitcoin() { LOGGER.info("Mining Bitcoin..."); while (alwaysTrue()) { // Empty body } LOGGER.info("Bitcoin mined!");
return new Bitcoin("bitcoin-hash");}private static boolean alwaysTrue() { return true;}Now, we can make it race with a thread that retrieves the repositories of a user:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository();
var repositories = race( () -> gitHubRepository.findRepositories(new UserId(42L)), () -> mineBitcoin() );
LOGGER.info("GitHub user's repositories: {}", repositories);}We expect to get the user’s repositories before the bitcoin is mined and see the race function to interrupt the mineBitcoin computation. We have already tested the race function and know it works as expected. However, the output of the execution is the following:
08:49:09.118 [virtual-22] INFO GitHubApp -- Mining Bitcoin...08:49:09.118 [virtual-20] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=42]'08:49:10.135 [virtual-20] INFO GitHubApp -- Repositories found for user 'UserId[value=42]'(infinite waiting)The main method executes forever despite the race function interrupting the mineBitcoin computation and all the good promises of structured concurrency. The problem is that the mineBitcoin computation doesn’t have a checkpoint for the interruption status of its thread. Since interruption is a cooperative mechanism, the mineBitcoin computation doesn’t know that the scope wants to stop it.
It’s easy to fix the problem. We can add a checkpoint in the mineBitcoin computation to check if the thread was interrupted. We can check if a thread was interrupted with the isInterrupted method on the Thread class:
static Bitcoin mineBitcoinWithConsciousness() throws InterruptedException { LOGGER.info("Mining Bitcoin..."); while (alwaysTrue()) { if (Thread.currentThread().isInterrupted()) { LOGGER.info("Bitcoin mining interrupted"); throw new InterruptedException(); } } LOGGER.info("Bitcoin mined!"); return new Bitcoin("bitcoin-hash");}It’s always a good idea to forward interruption to the parent thread throwing an InterruptedException exception. Moreover, adding a the InterruptedException exception to the method signature signals to the caller that the computation can be interrupted.
Now, we can retry the race function with the mineBitcoinWithConsciousness computation:
public static void main() throws ExecutionException, InterruptedException { final GitHubRepository gitHubRepository = new GitHubRepository();
var repositories = race( () -> gitHubRepository.findRepositories(new UserId(42L)), () -> mineBitcoinWithConsciousness() );
LOGGER.info("GitHub user's repositories: {}", repositories);}If we rerun the code, we can see from the output that the mineBitcoinWithConsciousness computation is interrupted after the user’s repositories are retrieved and the race function semantic is respected:
09:02:10.116 [virtual-22] INFO GitHubApp -- Mining Bitcoin...09:02:10.133 [virtual-20] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=42]'09:02:11.156 [virtual-20] INFO GitHubApp -- Repositories found for user 'UserId[value=42]'09:02:11.164 [virtual-22] INFO GitHubApp -- Bitcoin mining interrupted09:02:11.165 [main] INFO GitHubApp -- GitHub user's repositories: [Repository[name=raise4s, visibility=PUBLIC, uri=https://github.com/rcardin/raise4s], Repository[name=sus4s, visibility=PUBLIC, uri=https://github.com/rcardin/sus4s]]Calling the shutdown method prevents the scope from forking new tasks. The fork method will not start any new task if the scope is in the SHUTDOWN state. Let’s try it with a simple example:
public static void main() throws ExecutionException, InterruptedException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { scope.shutdown(); scope.fork(() -> { LOGGER.info("Hello, structured concurrency!"); return null; }); scope.join().throwIfFailed(); } LOGGER.info("Completed");}The execution of the above code will never print the message “Hello, structured concurrency!” since the scope is in the SHUTDOWN state when the fork method is called. Last but not least, all the forked subtasks that were not completed before calling the shutdown method on the associated scope will never trigger the invocation of the handleComplete method we saw previously.
We need to discuss the relationship between parent and children tasks in a structured concurrency context, one of its main features. However, we need a more articulated example to demonstrate how structured concurrency in Java manages the parent-children relationship.
Imagine we now want to retrieve the information of two GitHub users concurrently. Moreover, we want to retrieve them at most a given amount of time or give up otherwise. The signature of the new use case method is the following:
interface FindGitHubUserUseCase { // Omissis List<GitHubUser> findGitHubUsers(UserId first, UserId second, Duration timeout) throws InterruptedException, ExecutionException;}We all agree that a better signature must have a vararg or a list of users. However, the above signature is enough for our needs.
We have all the building blocks needed to implement the new use case. We want to have computation time limited. So, we’ll use the timeout function we implemented in the previous section. Then, we want to retrieve the information of both users concurrently, and we have the par function to do it. Let’s implement the new use case:
@Overridepublic List<GitHubUser> findGitHubUsers(UserId first, UserId second, Duration timeout) throws InterruptedException, ExecutionException {
var gitHubUsers = timeout(timeout, () -> par(() -> findGitHubUser(first), () -> findGitHubUser(second)));
return List.of(gitHubUsers.first, gitHubUsers.second);}The findGitHubUser is the method we implemented so far. Despite the conciseness of the code, the above code is an example of a tree of nested tasks. Let’s sketch the relationships among tasks as we did previously:
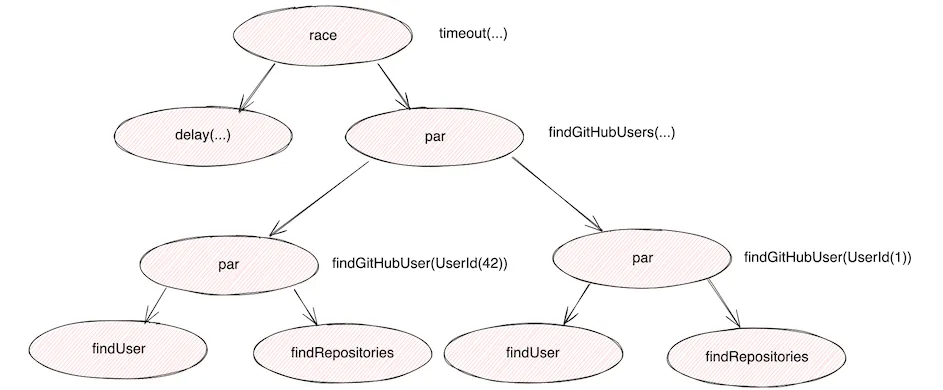
As we can see, we have at least three levels of nested computations. Now, it’s time to exploit the full power of structured concurrency. As we said, we want the whole computation to stop if it cannot be accomplished in a maximum amount of time. As we might remember, retrieving basic user information takes 500 milliseconds, while retrieving repositories takes 1 second. So, to see structured concurrency in action, we can set up the whole timeout to 700 milliseconds:
public static void main() throws ExecutionException, InterruptedException { var repository = new GitHubRepository(); var service = new FindGitHubUserStructuredConcurrencyService(repository, repository);
final List<GitHubUser> gitHubUsers = service.findGitHubUsers(new UserId(42L), new UserId(1L), Duration.ofMillis(700L));}The output of the execution is the following:
08:15:10.955 [virtual-32] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=1]'08:15:10.955 [virtual-30] INFO GitHubApp -- Finding repositories for user with id 'UserId[value=42]'08:15:10.955 [virtual-31] INFO GitHubApp -- Finding user with id 'UserId[value=1]'08:15:10.954 [virtual-29] INFO GitHubApp -- Finding user with id 'UserId[value=42]'08:15:11.480 [virtual-31] INFO GitHubApp -- User 'UserId[value=1]' found08:15:11.481 [virtual-29] INFO GitHubApp -- User 'UserId[value=42]' foundException in thread "main" java.util.concurrent.ExecutionException: java.util.concurrent.TimeoutException: Timeout of PT0.7S reached at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$ShutdownOnResult.resultOrThrow(GitHubApp.java:361) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.race(GitHubApp.java:372) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.timeout(GitHubApp.java:378) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp$FindGitHubUserStructuredConcurrencyService.findGitHubUsers(GitHubApp.java:284) at virtual.threads.playground/in.rcard.virtual.threads.GitHubApp.main(GitHubApp.java:428)First, we saw that the four leaves of the above tree started concurrently, with four virtual threads assigned to each leaf: virtual-29, virtual-30, virtual-31, and virtual-32. After more or less 500 milliseconds from the start of the computation, the two leaves that retrieve the user information are completed successfully. However, the two leaves that retrieved the repositories didn’t complete within the given interval. The scope stopped the computation, and the race function implementing the timeout function threw a TimeoutException exception as expected.
Again, appreciate that the above code does not have a thread leak. The scopes stopped all the forked tasks within four nested levels of computations.
How does the whole thing work? As we saw in the previous section, the core mechanism is thread interruption. The race function creates the outer scope inside the timeout function. The scope is a ShutdownOnResult, so it waits for the first result. The scope is waiting on the scope.join() statement:
static <T> T race(Callable<T> first, Callable<T> second) throws InterruptedException, ExecutionException { try (var scope = new ShutdownOnResult<T>()) { scope.fork(first); scope.fork(second); return scope.join().resultOrThrow(); // <-- The scope is waiting here }}When the thread waiting for the timeout expires, it throws a TimeoutException:
delay(timeout);throw new TimeoutException("Timeout of %s reached".formatted(timeout));Since one of the forked tasks completed (exceptionally), the ShutdownOnResult.handleComplete method is called. The handleComplete method calls the shutdown method on the scope:
@Overrideprotected void handleComplete(Subtask<? extends T> subtask) { switch (subtask.state()) { case FAILED -> { lock.lock(); try { if (firstException == null) { firstException = subtask.exception(); shutdown(); // <-- The scope is shutdown here } } finally { lock.unlock(); } }// ...As you should remember, the shutdown method interrupts all the threads forked by the scope:
// Java SDKprivate boolean implShutdown() { shutdownLock.lock(); try { if (state < SHUTDOWN) { flock.shutdown(); state = SHUTDOWN; interruptAll(); // <-- The threads are interrupted here// ...So, the shutdown will interrupt the thread executing the findGitHubUsers method. The execution of the findGitHubUsers method, after having forked the two tasks retrieving the information for UserId(1) and UserId(42), is now suspended on the ShutdownOnFailure.join method:
@Overridepublic List<GitHubUser> findGitHubUsers(UserId first, UserId second, Duration timeout) throws InterruptedException, ExecutionException { var gitHubUsers = timeout(timeout, () -> par( () -> findGitHubUser(first), // <-- Forked tasks () -> findGitHubUser(second) ) ); return List.of(gitHubUsers.first, gitHubUsers.second);}
// Uses the below `par` implementation
static <T1, T2> Pair<T1, T2> par(Callable<T1> first, Callable<T2> second) throws InterruptedException, ExecutionException { try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var firstTask = scope.fork(first); var secondTask = scope.fork(second); scope.join().throwIfFailed(); // <-- The scope is waiting here return new Pair<>(firstTask.get(), secondTask.get()); }}Since the owning thread was interrupted, the join method will throw an InterruptedException exception. The try-with-resources statement that calls the ShutdownOnFailure.close method catches the exception. First, the close method calls the shutdown method on the scope, which interrupts all the threads forked by the scope:
// Java SDK@Overridepublic void close() { ensureOwner(); int s = state; if (s == CLOSED) return; try { if (s < SHUTDOWN) implShutdown(); // <-- Shutting down the scope will interrupt the forked tasks flock.close(); } finally { state = CLOSED; } if (forkRound > lastJoinAttempted) { lastJoinCompleted = forkRound; throw newIllegalStateExceptionNoJoin(); }}If you remember, the implementation of the findGitHubUser method uses another instance of the par function:
@Overridepublic GitHubUser findGitHubUser(UserId userId) throws ExecutionException, InterruptedException { var result = par( () -> findUserByIdPort.findUser(userId), () -> findRepositoriesByUserIdPort.findRepositories(userId)); return new GitHubUser(result.first(), result.second());}The execution of the par method is waiting in the ShutdownOnFailure.join method, which will throw an InterruptedException exception…and the story goes on as we just saw. At first reading, the process could seem complex, but it’s not. For those of you who are familiar with UML sequence diagrams, here is a sequence diagram of the above use case:
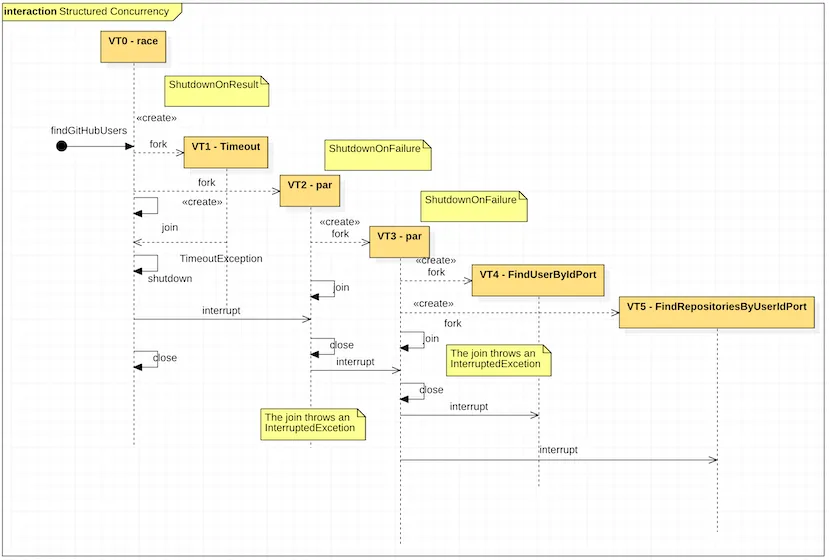
For the sake of simplicity, the diagram doesn’t show threads retrieving the information from GitHub for the second user, but it gives a nice picture of what happens in the code.
The above example introduced another piece in the structured concurrency puzzle in Loom: the StructuredTaskScope.close method. As we can see, it is central to force the contract between parent and children tasks. It’s a guard in case of exceptions thrown during the execution of a scope, like the InterruptedException exception in the above example. Moreover, if the parent scope reaches its intended result, it’s the last line of defense to ensure that all the children tasks that are not needed anymore are interrupted. Even though a custom implementation of a shutdown policy forgets to call the shutdown method on the scope, the close method will do it for us.
We finally reach the conclusions of the article. We introduced what structured concurrency is and what its benefits are. We saw it’s hard to avoid thread leaks using the traditional Java concurrency API. Fortunately, Project Loom is available in version 19 of Java. The project introduced virtual threads and structured concurrency. We saw the different shutdown policies that the JDK brings, and we implemented one custom policy to dive deep into the main concepts of structured concurrency. We were able to implement structured concurrency primitives that we find in many libraries like Scala ZIO and Cats Effect. Finally, we saw the parent-children relationship in structured concurrency in action and how the close method is the last line of defense to ensure that all the children tasks that are not needed anymore are interrupted.
I hope you enjoyed the article and learned something new. Thanks for reading, and I look forward to the next one!
As we promised at the beginning of the article, we provide the full pom.xml file:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion>
<groupId>in.rcard</groupId> <artifactId>virtual-threads-playground</artifactId> <packaging>jar</packaging> <version>2.0.0-SNAPSHOT</version> <name>Project Loom Playground</name>
<properties> <maven.compiler.source>23</maven.compiler.source> <maven.compiler.target>23</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties>
<dependencies> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.5.8</version> </dependency> </dependencies>
<build> <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (maybe moved to parent pom) --> <plugins> <plugin> <artifactId>maven-clean-plugin</artifactId> <version>3.2.0</version> </plugin> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.3.0</version> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.10.1</version> <configuration> <release>23</release> <compilerArgs>--enable-preview</compilerArgs> </configuration> </plugin> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0-M7</version> </plugin> <plugin> <artifactId>maven-jar-plugin</artifactId> <version>3.2.2</version> </plugin> <plugin> <artifactId>maven-install-plugin</artifactId> <version>3.0.1</version> </plugin> <plugin> <artifactId>maven-deploy-plugin</artifactId> <version>3.0.0</version> </plugin> <plugin> <artifactId>maven-site-plugin</artifactId> <version>4.0.0-M3</version> </plugin> <plugin> <artifactId>maven-project-info-reports-plugin</artifactId> <version>3.4.0</version> </plugin> </plugins> </pluginManagement> </build></project>Share on:
This site uses cookies. Check our cookie policy (TLDR: no personal information is stored). For more information see our cookie policy.